03 Apr 2012
Nantucket: an accidental limerick detector
How can you not name an accidental limerick detector Nantucket? I think there may be laws about that. Point being, I wrote a program that takes any text and tries to find any accidental limericks that might be hiding within (based on syllable counts and rhyme, ignoring punctuation and intent).
Limericks have a fairly loose form. The rhyme scheme is always AABBA, but the syllable count can be anything along the lines of 7-or-8-or-9/7-or-8-or-9/5-or-6/5-or-6/7-or-8-or-9. And as if that weren't loosey-goosey enough, they can have either anapaestic meter (duh-duh-DUM, duh-duh-DUM) or amphibrachic meter (duh-DUM-duh, duh-DUM-duh)!
So, rather than write a limerick detector that looks for anything even remotely resembling a limerick, I chose the following as the canonical example to work from (at least for now):
There was a young student from Crew
Who learned how to count in base two.
His sums were all done
With zero and one,
And he found it much simpler to do.
Going by the canonical example above, Nantucket is set to look for limericks that are AABBA (rhyme scheme) and 8/8/5/5/9 (syllable count per line). It currently ignores meter, but I may add that requirement in later. It also only looks at words through an American English accent.
How to implement such a thing? Well, I started simple - I used the CMU Pronouncing Dictionary ("cmudict") as accessed through NLTK (Python's natural language toolkit) to get each word's syllable count and pronunciation, and just had Nantucket give up on any potential limericks that included words not in cmudict. It tokenizes the text, then walks through each word in the text in turn, checks to see if there's a limerick starting with that word, and gives up if it hits a word it can't analyze or a limerick form violation (such as a word that overflows the end of a limerick line, or a rhyme scheme problem).
(It turned out I had to know Python or Java for the Stanford Natural Language Processing class I started two weeks ago. Er. Okay! This came in very handy as soon as I decided to build Nantucket last week - apparently Python has better natural language processing ("NLP") libraries than Ruby, so it was absolutely the right choice for this project.) (I want Python's scientific libraries, but with RSpec. Is that too much to ask?)
So, that was pretty fast to throw together. I defined a rhyme as being any pair of words which have identical last vowel sound plus all sounds following the last vowel sound. That's not precisely right in American English, but it's pretty damn close. This was easy to do with cmudict, because every vowel phoneme in cmudict ends with a digit denoting stress, but consonant phonemes never include digits.
So, that was a long bit of geekery. Time for a poetry break!
from Proust's Swann's Way:
bad conduct should deserve Was I
then not yet aware that what I
felt myself for her
depended neither
upon her actions nor upon my
was wonderful to another
How I should have loved to We were
unfortunate to
a third Yes if you
like I must just keep in the line for
to abandon the habit of
lying Even from the point of
view of coquetry
pure and simple he
had told her can't you see how much of
That was a fun start, but I really wanted to handle the tons of words that just aren't in cmudict. I tested Nantucket on James Joyce's Ulysses repeatedly throughout this process, to come up with fantastic lists of words I was failing to catch at every step along the way.
I like to break projects down into small enough chunks that I get a sense of accomplishment frequently enough to keep myself motivated to keep on pushing forward. Here, words naturally fell into two categories - words which land in the middle of a line in a potential limerick, and words which land at the end of a line of a potential limerick. Syllable count matters for both, but I only really care about pronunciation for words that have to rhyme.
Next step was to create a function that determines the approximate number of syllables in any given word. A syllable contains a vowel sound, which can map to anywhere from 0 to 3 vowel graphemes (letters, not sounds) (aeiouy). I figured I could count the vowel grapheme groups, add 1 for each grouping of more than one vowel grapheme that isn't a common digraph (group of graphemes that generally signifies a single phoneme (sound)), add 1 for the common apostrophe-in-place-of-vowel instances, and subtract 1 for the circumstances where 'ed', 'es', or 'e' are likely silent at the end of a word, and get pretty close.
def approx_nsyl(word):
digraphs = ["ai", "au", "ay", "ea", "ee", "ei", "ey", "oa", "oe", "oi", "oo", "ou", "oy", "ua", "ue", "ui"]
# Ambiguous, currently split: ie, io
# Ambiguous, currently kept together: ui
digraphs = set(digraphs)
count = 0
array = re.split("[^aeiouy]+", word.lower())
for i, v in enumerate(array):
if len(v) > 1 and v not in digraphs:
count += 1
if v == '':
del array[i]
count += len(array)
if re.search("(?⟨=\w)(ion|ious|(?⟨!t)ed|es|[^lr]e)(?![a-z']+)", word.lower()):
count -= 1
if re.search("'ve|n't", word.lower()):
count += 1
return countWith that in place, I had Nantucket keep going when it came across non-cmudict words that fell in the middle of potential limerick lines, but give up on any potential limerick that hit a non-cmudict word that would fall at the end of a limerick line and have to rhyme. Better, but not good enough. I needed a way to figure out when words not in cmudict rhyme!
Grapheme-to-phoneme conversion ("g2p"), or converting a list of letters into a corresponding list of sounds, is a fascinating and non-trivial problem. I spent a lot of time falling down the rabbit hole of reading intriguing papers on how to design machine-learning algorithms that can take context into account when doing g2p. There are two big problems with g2p in American English. First, there's the issue of alignment - there just isn't a consistent correspondence between the number of graphemes and the number of phonemes. And second, there's the issue of context - the same grapheme (or group of graphemes) can correspond to a different phoneme depending on the other graphemes in the word (think about the "pol" in "politics" (ah) versus "political" (uh)), or even whether the word is a verb or a noun (the "de" in "defect", for instance (dee versus deh)).
At a glance, I figured I could do a rough pass at the problem by creating a last-syllable dictionary based on cmudict, which I promptly did. It was actually surprisingly helpful, but still missed a lot of words, and wasn't as accurate as I wanted it to be. (More on this later.) So, I kept thinking and reading about the problem.
Poetry break!
from James Joyce's Ulysses:
grace about you I can give you
a rare old wine that'll send you
skipping to hell and
back Sign a will and
leave us any coin you have If you
then he tipped me just in passing
but I never thought hed write making
an appointment I
had it inside my
petticoat bodice all day reading
meant till he put his tongue in my
mouth his mouth was sweetlike young I
put my knee up to
him a few times to
learn the way what did I tell him I
The most promising idea I came across is implemented as free software already as Sequitur (that link links to the paper it's based on, but you can also find a a free pre-publication copy of the manuscript here). It uses expectation maximization and viterbi training to create a model for g2p for any language, given a suitable dictionary to train from first. (It argues that it's method is better than other methods I came across earlier, which generally involved hidden markov models or, in the simplest promising paper I read, going from right to left and looking at three graphemes to either side for context).
So, I installed Sequitur and gave it a whirl, training and testing it with huge portions of cmudict. It took hours to train, though, and I ultimately wasn't thrilled with its accuracy. (To be fair, I only tested its accuracy overall, not its accuracy for last syllables only).
It occurred to me during this process that my needs were actually simpler than that. I don't need to be able to do g2p for complete words in order to have a functional limerick detector. I only need to do g2p for the last syllable of each end-of-limerick-line word. That simplifies my alignment problem right off the bat, because I start by aligning my grapheme list and my phoneme list to the right (as in the second paper I link to above), and I don't go far enough to the left for them to have much opportunity to become misaligned to any relevant extent. It also resolves a large portion of my context problem - there's less flexibility in last-syllable graphones (pairs of graphemes and phonemes) than in entire-word graphones.
As completely fascinated by machine learning algorithms as I am, I decided to go back to the last-syllable dictionary I'd created and see if I could attack the problem by improving its accuracy instead.
I created it by going through every word in cmudict and pulling it out what looked like the last syllable worth of graphemes and the last syllable worth of phonemes, catching the graphemes with:
graphemes = re.search("((?i)[BCDFGHJKLMNPQRSTVWXZ]{1,2}[AEIOUY]+[BCDFGHJKLMNPQRSTVWXZ]*(E|ED)?('[A-Z]{1,2})?)(?![a-zA-Z]+)", word).group()And catching the phonemes with:
val = min(vals, key=len)
i = -1
while i >= 0 - len(val):
if isdigit(val[i][-1]):
str = " ".join(val[i:])To improve my accuracy, after a few iterations I chose to grab up to 2 consonants prior to the my best estimate of the last vowel sound in the word, and include copies without the first and without either, in my list. For example:
clotted AH0 D
lotted AH0 D
otted AH0 D
ders ER0 Z
ers ER0 Z
rs ER0 ZThis gave me gleeful flashbacks to a childhood parlor trick that my brothers and I can still all do in unison, where we chant at blazingly fast top speed: "everybody-verybody-erybody-rybody-ybody-body-ody-dy-y!"
Poetry break!
from Dostoevsky's The Brothers Karamazov:
eyes with a needle I love you
I love only you Ill love you
in Siberia
Why Siberia
Never mind Siberia if you
are children of twelve years old who
have a longing to set fire to
something and they do
set things on fire too
Its a sort of disease Thats not true
and be horror struck How can I
endure this mercy How can I
endure so much love
Am I worthy of
it Thats what he will exclaim Oh I
Anyways, once I had modified set of last syllable graphones (pairs of letter lists and sound lists), I used some sweet little command line tools to sort the results into a list of unique types with frequency counts, like so:
sort < suff_a.txt | uniq -c | sort -nr > suff_b.txtMy last step in creating my cmudict-based last-syllable dictionary ("suffdict") was to keep only the most likely set of phonemes for each unique set of graphemes, and reformat the list to match cmudict's format so I could just use NLTK's cmudict corpus reader for my suffdict as well. I did that like so:
def most_prob(file):
uniq_suffs = []
goal = open('suff_c.txt', 'a')
with open(file) as f:
for line in f:
suff = re.search("\s[a-zA-Z']+\s", line).group()
if suff not in uniq_suffs:
uniq_suffs.append(suff)
new_line = re.sub("\d+\s(?=[a-z])", "", line)
new_line = re.sub("(?<=[a-z])\s(?=[A-Z])", " 1 ", new_line).strip()
goal.write(new_line + '\n')
goal.close()The above code catches only the first instance of any given grapheme set, which gives me the most probable instance, because I'd already sorted everything in order of highest to lowest number of occurrences.
Now when checking for last-syllable phonemes for a word not in cmudict, I use the same regex I used when creating suffdict to check whether the last syllable worth of graphemes from that novel word is in suffdict, and if so, return the corresponding last syllable worth of phonemes from suffdict. If not, try without the first letter, or without the s or 's at the end.
Fantastic! I was then able to test my accuracy by running every word in cmudict through cmudict and through my suffdict, and then seeing whether the resulting phoneme lists rhymed.
Poetry break!
from Mark Twain's Huckleberry Finn:
he suspicion what we're up to
Maybe he won't But we got to
have it anyway
Come along So they
got out and went in The door slammed to
and see her setting there by her
candle in the window with her
eyes towards the road and
the tears in them and
I wished I could do something for her
I went through a few iterations of tweaking my suffdict creation method to eke a few extra percentage points of accuracy out of it.
My first attempt, which looked at every possible pronunciation for every word in cmudict when creating my suffdict, gave me 80.29% accuracy.
Next, I realized that since I was always using the shortest possible pronunciation when running words through cmudict, I should probably only look at shortest possible pronunciations when creating my suffdict, for consistency's sake. That brought me up to 82.20% accuracy.
After that, it occurred to me that if I included up to 2 consonants at the beginning of each last-syllable grapheme list in suffdict instead of just 1, I would have a bit more context and catch a few more words correctly. Which I did! That got me up to 85.78% accuracy.
This was getting pretty exciting, but still not as good as I wanted it to be. I thought about what I was doing, and decided to revisit the function I'd written that checks whether lists of phonemes (in the cmudict-style, but from any source) rhyme. Maybe the problem was there instead.
And, oh, yes! My rhyme_from_phonemes function was checking to see whether the last vowel phoneme and all phonemes thereafter were identical in both words - really, truly identical, that is. It disqualified even pairs of words that had exactly the same sounds but different stress patterns. This might make sense if I were paying attention to meter or defining rhyming differently, but it wasn't really what I was going for here at all. So, I rewrote that function to ignore the digit of the last vowel phoneme (which denotes stress only) and instead check whether it and all following phonemes were otherwise identical, like so:
def rhyme_from_phonemes(list1, list2):
i = -1
while i >= 0 - len(list1):
if isdigit(list1[i][-1]):
if i >= 0 - len(list2) and list1[i][:-1] == list2[i][:-1] and (i == -1 or list1[i + 1:] == list2[i + 1:]):
return True
else:
return False
i -= 1That brought me up to 90.85% accuracy.
That feels pretty good, for my purposes!
I was now catching limericks with novel words at the end of lines. Poetry break time!
from Genesis:
in the iniquity of the
city And while he lingered the
men laid hold upon
his hand and upon
the hand of his wife and upon the
Amorite and the Girgasite
And the Hivite and the Arkite
and the Sinite And
the Arvadite and
the Zemarite and the Hamathite
I took a moment after that to make the basic limerick-finding algorithm a bit faster. My first draft was intentionally simple but inefficient, in that it started fresh for each word in the text, instead of saving the syllable counts and phonemes for words checked on previous limerick attempts. It had to re-analyze a word each time that word was encountered.
That worked well enough to let me get to the interesting g2p problem quickly, but once I was reasonably satisfied with my suffdict, I wanted to refactor to make the whole thing more efficient. The current version holds the phonemes and syllable count of each word encountered in a dict, so it can grab them quickly from that dict the next time they're encountered instead of having to figure them out from scratch again and again as it goes through the text.
I have some thoughts on increasing the efficiency further (by having it skip forward more intelligently whenever it hits a word it can't find phonemes for, for instance), but really, it's at a good enough stage that I wanted to share some accidental limericks with you all already!
30 Mar 2012
Kenobi: a naive Bayesian classifier for Ask Metafilter
I built Kenobi as a way to get my feet wet with machine learning.
A fellow Recurser had mentioned the idea of a naive Bayesian classifier to me, and my ears perked up - Bayes! Hey, I know Bayes' Theorem! It's a generally useful simple equation that helps you figure out how much or how little to take new evidence into account when updating your sense of the probability of something or other.
The basic idea is: 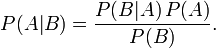
Wait, no, the basic idea is that evidence doesn't exist in a vacuum. Bayes' Theorem is a way of quantifying how to look at new evidence in the context of what we know already and understand how we should weigh it when taking it into account, and how to determine more accurate probabilities and beliefs given the evidence we have to work from. If you're looking for a more detailed understanding, I highly recommend reading Yudkowsky's particularly clear explanation of Bayes' Theorem.
(I went to a rationalist party once. Some guy asked me, "Are you a rationalist?" The friend who'd dragged me to the party interrupted with, "Well, she's not not a rationalist!" And there you have it, I suppose.)
So, that seemed like fun. I'd just finished working on a card game implementation that can run simulations of strategies to help my partner with his game design (Greenland), and was ready for a new project. But a spam filter seemed dull - it's been done before. Repeatedly. So, what to do?
I'm a huge fan of Ask Metafilter, a community where folks ask questions (shocking, no?) and answer questions asked by others. My fabulous brother got there first, and I appreciate that he dragged me in with him. It can be a bit overwhelming, though. I don't really have the time to skim through all the questions that get posted, especially since so many of them are about things where I have no useful information or advice to give. It sure would be helpful if something pared the list down to only the questions where my answers would be most likely to actually help others, right? Right!
Kenobi was a perfect combo project for me. I got to explore machine learning, use some of the skills I picked up at the awesome ScraperWiki class on web scraping I took a while back, and create a tool I'd actually use to improve my ability to help others. Right on.
So, what does Kenobi actually do?
Kenobi has two basic functions: analyzing answers you've already posted to old AskMeFi questions, and classifying new questions for you to pick out the ones you can answer best.
To analyze your old AskMeFi data, Kenobi:
- deletes outdated training data for you from its own database, if any;
- logs into Metafilter under a spare account I created for this purpose, because one can't see favorite counts in user profile comment data unless one is logged in;
- searches to find the user ID number associated with your username;
- scrapes the answers section of your profile for the above-the-cut text of each question you've answered, and whether or not you've received at least one favorite on the answer(s) you posted to that question;
- separates the old questions into a "should answer" group (those where your answer(s) did get at least one favorite) and a "should NOT answer" group (those where your answer(s) didn't get any love);
- organizes and saves the data from each group ("should answer" and "should NOT answer") to refer back to when classifying new questions;
- compresses the data to save space in the database; and
- emails you to let you know that training is done, if you submitted an email address (highly recommended).
To classify new AskMeFi questions for you, Kenobi:
- clears out your last batch of results, if any;
- parses the Ask Metafilter RSS feed for above-the-cut question text and URLs for the n most recent questions;
- decompresses the data it has on you into memory;
- for each question, determines the probability that you should answer it and the probability that you should NOT answer it, based on Bayes' Theorem and your old answer data;
- for each question, if the odds that you should answer it is at least 4.5 times higher than the odds that you should NOT answer it, classifies that question as good for you to answer;
- saves and displays only and all the new question that are classified as good for you to answer.
Why do the odds that I should answer a question have to be 4.5 times higher than the odds that I should NOT answer that question, for Kenobi to classify it as good for me?
Because when I left the threshold lower, people were getting too many questions that didn't seem like good fits to them. With a higher threshold, some folks may not get any results at all (sorry!), but people who've answered enough past AskMeFi questions to give good data to work from will get much more accurate results.
The closer the two probabilities are, the less confident we can be that we've really found a good match and that the question really is a good one for you to answer. It only makes sense to select a question for you when the odds that it's the kind of question you're good at answering are significantly higher than the odds that it isn't.
Why all that compressing and decompressing?
I wrote Kenobi up as a pure Ruby command line tool first, then decided it would be fun to quickly Rails-ize it so more people would be able to play with it more easily. That meant finding a place to deploy it, as easily and cheaply as possible.
Heroku (my host) charges for databases over 5mb. I love you all, but not enough to spend money on you if I don't have to. I'm trying to be as efficient as possible here, in hopes of not going over and having to actually spend money on this project if I can possibly avoid it.
Why the wait while Kenobi analyzes my old data?
A few reasons!
First, one can't actually effectively search Metafilter for a user by name or see favorite counts on the list of a user's past answers in their profile unless one is logged into Metafilter. Metafilter doesn't even have an API to work with. It does have info dumps, but they're huge and not updated regularly.
This means that Kenobi has to arduously scrape and parse the html for Metafilter whenever it analyzes old data for a new user. And it has to actually log into the site and click through as a logged-in user to do so, which it does using a gem called Mechanize.
I set the scraping up as a background task with Delayed_Job and set Kenobi up to email people when ready, so no one had to sit around staring at an error message or colorful spinner while waiting for their analysis to come up in the job queue and get done. This meant that there were no more http timeout error, but it also means that your analysis job goes to the end of the queue, however long it may be.
Also, Heroku charges for worker dynos, which are needed to actually run the background processes piling up in that job queue. They charge by the second. (Seriously). But that includes all the time the worker spends sitting around waiting for a job to exist, not just the time it spends actually working on jobs.
This was just a learning project, not something I actually expect to earn anything from or want to pay anything for. So, I spent a bunch of time messing around with a nifty tool called Workless and learning how to have Heroku automatically scale a single worker dyno up and down as jobs are added and completed, so I can pay for as little time as possible.
This slows things down for you even more, because not only are you waiting for the scraping to get done, you're actually waiting for Heroku to start up a new worker dyno to start working on the scraping before it can get done.
Sorry about that! If you care a lot for some reason, email me and we can commiserate or something.
Wait, so Kenobi picks out questions where my answers will help others, not questions that help me directly?
That's right! Kenobi's selections are based on each new question's similarity to the past questions to which your answers have been favorited by others, and dissimilarity to the past questions where your answers got no love. It doesn't pay attention to what you've favorited - only to which of your answers have been favorited by other people. It doesn't really care about your interests at all, other than your interest in being popular of use to others.
Have fun!
13 Feb 2012
Considerating
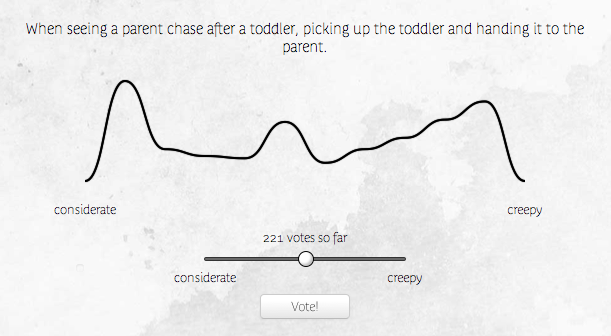
Considerate or creepy? It can be hard to tell, sometimes! My brother Josh asked me to be his "empathy sherpa" and help him navigate that blurry grey line between sweet and skeezy (or maybe that's a different project?), so I built Considerating for him while warming up for Recurse Center.
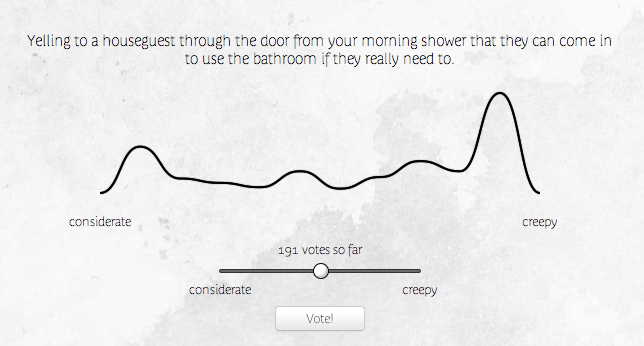
Considerating is a simple concept. Each consideration comes with a slider (or dropdown, on mobile browsers) that lets you vote - where on the range between considerate and creepy does this idea fall? You can sign in with Google oauth to submit new considerations of your own. After each vote, the graph is recalculated and redrawn to accurately reflect the updated results.
I did all the coding, and Josh and I collaborated on the design and UI. It was really fun to finally work on a project like this with him! I mean, this is my little brother, the kid who once tried to evict me from my bedroom back when we were young by taping a sign to my door while I was out signed by the "MGMT" - and the person who can most consistently answer correctly when I call him out of the blue to ask, "Hey, what's that word I'm forgetting?"

My favorite part of this project was the little bit of javascript that makes those whoopety whoopety graphs work out. The code is all here, but this is the particularly fun bit:
function draw(points) {
var canvas = document.getElementById('graph<%= @consideration.id %>');
var highest = Math.max.apply(Math, points);
if (canvas.getContext){
var ctx = canvas.getContext('2d');
ctx.strokeStyle = "#000000";
ctx.lineJoin = "round";
ctx.lineWidth = 2;
ctx.beginPath();
ctx.moveTo(0,115);
ctx.bezierCurveTo(20, 115,
20, 115-(points[0]/highest)*100,
40, 115-(points[0]/highest)*100);
for (i=1; i<10; i++) {
ctx.bezierCurveTo(20+(i*40), 115-(points[i-1]/highest)*100,
20+(i*40), 115-(points[i]/highest)*100,
40+(i*40), 115-(points[i]/highest)*100);
}
ctx.bezierCurveTo(420, 115-(points[9]/highest)*100,
420, 115,
440, 115);
ctx.shadowColor="black";
ctx.shadowBlur=1;
ctx.stroke();
}
}Imagine the graph as a set of 10 bars. The drawing function takes an array of 10 values, and creates those smooth curves between points set at the intersection of each bar (x-axis) and the number of votes that value has received, scaled appropriately (y-axis).
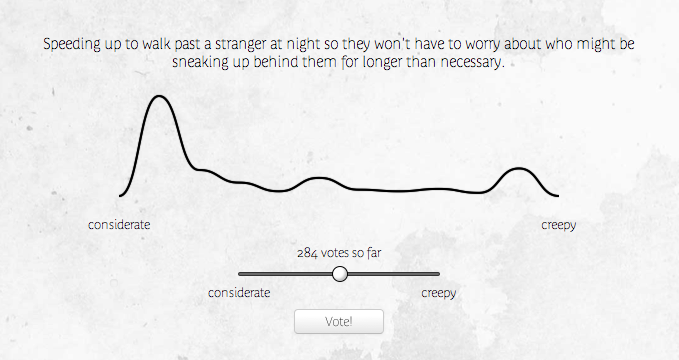
I'd played with Adobe Illustrator before, and had some sense of how bezier curves work. But it was a lot of fun to have to think through the math that would get me what I wanted from scratch, without being able to rely on click-and-drag visuals. I have a much more solid understanding of what bezier curve control points actually mean now, which I'm really happy about.
I still don't know if I can get away with chasing after strangers' toddlers, though. C'mon, internet, help me figure it out!
19 Nov 2011
Jailbreak the Patriarchy: GitHub, Press, & Favorite Examples
You ask for it, so you got it - I put the source code for Jailbreak the Patriarchy up on GitHub. Feel free to check it out, contribute, or use it to make your own extensions. Have fun!
I'm staggered and delighted by the responses to my little extension. I'm still not bored of watching people tweet their reactions or examples of swaps they've come across and liked best! Here's a bit of a roundup of the press it's received:
• I was interviewed on APM’s Tech Marketplace. Thank you, public radio! I think you just made my month. My segment starts at 2:35 in that recording.
• The New Yorker mentioned me! Of course, they rather hilariously proved my point by writing: “Jezebel tests the new Google Chrome extension Jailbreak the Patriarchy, which feminizes nouns and pronouns on any Web site.” Only in a world in which the default is masculine can gender-swapping be described as “feminizing”.
• Jezebel: Fun Chrome Extension Gender-Swaps The Internet
• Flavorwire: Re-gender Your Webpages with the New “Jailbreak the Patriarchy” Chrome Extension
• The Toronto Star: Woman! I feel like a man: Swap gender of words from your browser
• The Mary Sue: You Should Really Check Out Google Chrome’s Genderswap Plugin
• Cyborgology has perhaps the most thoughtful response I’ve read yet.
• Gina Carey: Swapping Gender in Books - “Humbert Humbert is a middle-aged, fastidious college professor. She also likes little boys.”
• Prosumer Report: Genderswap Your View of the World
• Maria Popova (brainpicker) declared Jailbreak the Patriarchy to be the “best Chrome extension ever - wow!
• And so many more! I’m pretty thrilled to have excited Kelley Eskridge, who’s pretty exciting herself. Morning Quickie suggested using Jailbreak in sociology or history classes (and women’s studies, of course). I made it onto Metafilter and Reddit. I love Ellen Chisa’s response. I probably shouldn’t admit to this, but I actually found some thoughtful discussion on gendered language over on the Sensible Erection forum discussion (includes NSFW images) of Jailbreak the Patriarchy.
• Not to mention all the other fabulous folks on Twitter who said wonderful things and quoted some great swaps they were finding: Jonathan Haynes and Oliver Burkeman of the Guardian, Zach Seward of the Wall Street Journal, Julian Sanchez of Reason Magazine, Charlie Glickman of Good Vibrations, Elizabeth Bear, Bloomsbury Press, TrustWomen, ResearchGate, Disinfo, and more. Even GRAMMARHULK seemed excited!
Thank you, everyone! I love seeing all your examples and hearing your responses. I've had an amazing week, seeing everyone react to this thing I built. What a trip!
If you haven't checked it out yet, I suggest you go install Jailbreak the Patriarchy and then read pages such as Schrodinger's Rapist or the art of being an ambitious female. Or perhaps the "relationships" tag on Ask Metafilter. Check out the news on the latest sex/harassment/abuse scandal, the latest corporate scandal, the latest big thing in business or politics. And for best effect, leave it installed for a few days, let yourself forget that it's there, and see what jumps out and surprises you.
Also, ports and spin-offs created by other coders: </p> • Nicholas FitzRoy-Dale ported Jailbreak to work for Safari • sinxpi ported Jailbreak to a Greasemonkey script for Firefox • Marianna Kreidler released a gender-neutral version of Jailbreak
11 Nov 2011
Jailbreak the Patriarchy: my first Chrome extension
I just released my first Chrome extension! It's called Jailbreak the Patriarchy, and if you're running Chrome, you can head over here to install it.
What does it do?
Jailbreak the Patriarchy genderswaps the world for you. When it's installed, everything you read in Chrome (except for gmail, so far) loads with pronouns and a reasonably thorough set of other gendered words swapped. For example: "he loved his mother very much" would read as "she loved her father very much", "the patriarchy also hurts men" would read as "the matriarchy also hurts women", that sort of thing.
This makes reading stuff on the internet a pretty fascinating and eye-opening experience, I must say. What would the world be like if we reversed the way we speak about women and men? Well, now you can find out!
What if you need to read something on the web exactly as it was written?
Running this extension will not trap you outside the asylum. When you install Jailbreak the Patriarchy, you'll see that there's a new button in the top right corner of your browser. It looks like this:
When you click that button, it basically toggles the patriarchy. If Jailbreak the Patriarchy is active when you click, it pauses the extension and reloads your current tab back into reality. If the extension is already paused when you click the button, it unpauses the extension and reloads your current tab back into genderswapped-land.
Just to be clear, only your current tab will reload automatically, but the pause/unpause is browser-wide and persists until you toggle the button again. It's easy to tell when the extension is paused, because the button in the browser will get a big red OFF tag, like so:

I found it helpful to pause the extension while writing this post, for instance, and intend to unpause it as soon as I'm done. No big deal, with that toggle button right in the browser at all times.
Why create such a thing?
I was having dinner with the incomparable Jess Hammer a couple weeks ago, when the topic of ebooks came around. I made an offhand comment about how someone really ought to make an app that toggles male/female characters' genders in ebooks, and promptly started thinking about what I was really looking for along those lines.
I'm not much an ebook reader myself, so a Chrome extension feels much more useful to me. But it absolutely genderswaps html-formatted Project Gutenberg books, if that's what tickles your fancy.
Running Jailbreak the Patriarchy for the past few days has already changed my perspective on the world in a way that I find interesting, enjoyable, and valuable. I'm very curious to hear how other folks feel about the experience! So please give it a try, and let me know whether and how it affects your perspective!
Are there any bugs?
There is a known bug with the English language itself that I'm dealing with imperfectly at the moment. See, sometimes "her" should translate to "him", and sometimes it should translate to "his". There are a lot of tricky edge cases here.
I have a set of rules that recognize the most common cases where "her" always or usually should translate to "him", and then a rule that translates all remaining instances of "her" to "his" instead. It's a decent system, but not yet thorough enough. (Better than it was when I started, though. Extra thanks to Molly Tomlinson and Xtina Schelin for helping me get this as close to accurate as it is already!) This is very much a work-in-progress.
What this ultimately means is that sometimes you're going to see "his" where you really ought to see "him" instead, or vice-versa. You can help fix that! You don't need to know Javascript to help - just knowing English is more than good enough! If you come up with any simple rules on when "her" ought to go to "him" but currently doesn't, let me know, and I'll update the extension to take care of those cases as well.
Beyond that, so far I know that Jailbreak the Patriarchy doesn't affect gmail (which is very important to me), but I haven't tested it on any other email sites. It works on twitter, greader, and facebook, but I haven't tested it on dynamic content sites beyond that. Please let me know if you find any problems, and I'll figure out how to deal with them and push an update through.
Other Notes
Although Jailbreak the Patriarchy does swap gendered terms beyond pronouns, I've undoubtedly missed some that I'd be happy to add in as we notice them.
That said, I've decided so far not to genderswap some categories of gendered terms, like certain popular slurs. I reserve the right to change my mind and am open to hearing feedback on this decision.
I've also decided not to genderswap people's names, despite having some great theories on how to make that work if I wanted to. I have three reasons for this decision: I wanted to release this so we could play with it ASAP and figured I could always add that feature in later if I so choose; I think that although name-swapping would be great for an app that only affected works of fiction, changing people's names all over the web would blur reality to the point of inconvenience; and last, I'm really just charmed by the way it makes the entire world feel a bit more genderqueer to me.
Ports and spin-offs created by other coders:
• Nicholas FitzRoy-Dale ported Jailbreak to work for Safari
• sinxpi ported Jailbreak to a Greasemonkey script for Firefox
• Marianna Kreidler released a gender-neutral version of Jailbreak
</i>