05 Jan 2014
The best books I read in 2013
Tech-related books I loved reading in 2013
Emergent behavior
- Turtles, Termites, and Traffic Jams: Explorations in Massively Parallel Microworlds by Mitchel Resnick - Thoughts on experiments in emergent behavior using a Logo variant.
- Vehicles: Experiments in Synthetic Psychology by Valentino Braitenberg - I maybe kinda have a thing for the concept of emergent behavior. I blame having read Hofstadter at age 14-ish.
Design
- Practical Object-Oriented Design in Ruby by Sandi Metz - This was the sort of technical book you can both read on the train and actually get something valuable out of, which is a bit of a rare combination.
- Confident Ruby by Avdi Grimm - Guarding the borders.
- The Unix Philosophy by Mike Gancarz - “Every program written since the dawn of computing is a filter.”
Problem-solving
- Working Effectively with Legacy Code by Michael C. Feathers
- How to Solve It: A New Aspect of Mathematical Method by G. Polya - This is an extraordinary book. It claims to be about solving math problems, but of course it applies to problem-solving generally. No hugely new-to-me ideas, but I was mostly reading it for help articulating concepts when trying to teach debugging techniques, and it’s great for that.
History
- Engines of the Mind by Joel Shurkin - Includes lots of good stories about Ada Lovelace and von Neumann (why didn’t anyone ever tell me he was a Hungarian Jew with a penchant for dirty limericks?!).
- Coders at Work by Peter Seibel
Functional
- The Little Schemer by Daniel P. Friedman and Matthias Felleisen - Started off with a bunch of stuff I already knew (yeah yeah recursion whatevs), and then in the last maybe 30ish pages it suddenly sped up and got fascinating and brilliant and wonderful.
- Understanding Computation by Tom Stuart - Walks through automata, turing machines, lambda calculus, &c, writing interpreters and parsers along the way.
- Coffeescript Ristretto and Javascript Allonge by Reginald Braithwaite - Clear explanations of closures, combinators, &c.
- Learn You Some Erlang for Great Good! by Fred Hebert - Okay, I confess, I still haven’t actually finished reading this one yet, but I’d never written any Erlang before starting it and now I have, so it’s definitely been useful already.
Other
- The Tangled Web: A Guide to Securing Modern Web Applications by Michael Zalewski - Tremendously useful introduction to where things can go wrong.
- Learn Vimscript the Hard Way by Steve Losh
- The Unix Programming Environment by Brian Kernighan and Rob Pike - I’m only almost done with this at the moment, but I read most of it in 2013, so it totally still counts.
- A Unix Shell in Ruby by Jesse Storimer - Reading this made it finally click in my head what a shell is and isn’t, I think. The turtles are revealing themselves.
- Ruby Under a Microscope: An Illustrated Guide to Ruby Internals by Pat Shaughnessy - Wonderfully clear explanations of how MRI especially works. My favorite bits were the step-by-step explanations of C snippets along the way. Worth reading for the sake of learning about compilers, even if you’re not interested in Ruby.
Books I loved reading in 2013 that were emotionally difficult:
- Torture and Democracy by Darius Rejali - Riveting, intense, emotionally difficult. I would urge everyone to try to read this book, but I wouldn’t blame anyone for deciding it was too dark to handle. The history of torture and how different governments use different techniques, their goals, their lineage, and how public scrutiny has led to the proliferation of clean torture (that which does not leave marks) rather than lessening torture.
- In the Heart of the Sea: the Tragedy of the Whaleship Essex by Nathaniel Philbrick - I found that by the time the humans were dying of dehydration and starvation, I found it a bit hard to have sympathy for them, having just read so much detail about what they’d done while whale-hunting.
- The Glass Castle by Jeanette Walls - A novel that reminded me of some people I’ve known. This book tore me to pieces. Basically, it was a spectacular book that made me feel like I was going to throw up all the way through.
- The Testament of Jessie Lamb by Jane Rogers - Creepy as fuck novel. I’d stick it near The Handmaid’s Tale if my shelves were organized more organically. Themes of family and feminism and right to control over one’s own body.
Fiction I loved re-reading in 2013:
- A Deepness in the Sky by Vernor Vinge - The best of Vinge. Best read in quick succession with Elizabeth Moon’s The Speed of Dark.
- No one belongs here more than you. by Miranda July - Amazing short stories.
- Hereville: How Mirka Got Her Sword by Barry Deutsch - Still LOVE it. A comic book about an Orthodox Jewish girl fighting a troll.
Other Fiction I loved reading in 2013:
- Heiresses of Russ 2012: the year’s best lesbian speculative fiction edited by Connie Wilkins and Steve Berman - A bunch of truly fantastic stories!
- The James Tiptree Award Anthology 3 edited by Karen Jay Fowler, Pat Murphy, Debbie Notkin, and Jeffrey D. Smith - These are the best anthologies.
- The Quantum Thief by Hannu Rajaniemi - A bit Charles Stross, a bit Alistair Reynolds, a lot good.
- Emissaries From the Dead by Adam-Troy Castro - Decent scifi, made great by the presence of a character who is comprised of two linked humans who have transitioned into a single person and who has to deal with a lot of the same issues as trans people in our society.
- Civilwarland in Bad Decline by George Saunders - Short story and novella collection. His characters all have the same voice, but it’s a voice that really speaks to me. Marvelous satire, resignation, acknowledgment of futility, sharply hilarious and depressing all at once.
- Neptune’s Brood by Charles Stross - Financial mystery and space travel!
- Code Name Verity by Elizabeth Wein - I’m incredibly burnt out on Holocaust stories, and I still loved this one. (My grandparents were in Auschwitz. Ask me what my grandmother says about Dr. Mengele sometime, I dare you.)
- A Naked Singularity by Sergio de la Pava - A novel of philosophy and the NYC criminal justice system. Deeply nostalgic for me - this must’ve been written by someone who has actually spent time in the NYC criminal courts.
Other non-fiction I loved reading in 2013:
- Into Thin Air by Jon Krakauer - Memoir of disaster when climbing Everest.
- Positively Fifth Street by James McManus - Poker and murder. Good, though I think I would’ve enjoyed it more if I actually understood poker. It kinda makes me want to finally learn to play, though.
- Debt: The First 5,000 Years by David Graeber - I wouldn’t take this as a serious history, but I found it sociologically fascinating regardless.
- Central Park in the Dark: More Mysteries of Urban Wildlife by Marie Winn - I want to hang out in the park now and find owls and identify moths and watch slug sex!
Total number of books read in 2013: 123
15 Dec 2013
Virex: a Vim-flavored Regex playground on the web
/ vi[RE] / x
a tool for exploring regular expressions in vim
I've been goofing around with Vim and Erlang lately, and since two great tastes taste great together, I made you a thing! My latest toy - Virex, where you can experiment with Vim's regex on the web. It's like Rubular but for Vim regex. Have fun!
I've been having a lot of fun mucking around with learning and tweaking my Vim-related toolset ever since I started working at Case Commons, so when a coworker asked why there wasn't anything like Rubular for Vim's regex, I jumped at the excuse to throw this together.
Using Virex is slower than just experimenting in Vim locally, natch, but it was fun to build and it comes in handy when you're out with your friends arguing about regular expressions in Vim with only your phone handy for trying to prove your point. (SHUT UP, this happens.)
The interesting part turned out to be thinking about security, which is what the rest of this post will mostly be about.
Erlang is handy for sending messages between processes (shocking, n/n?)
I wanted to delegate the user-input test strings and regex patterns directly to Vim rather than try to reimplement Vim's regex perfectly, while avoiding sending anything through the shell (danger zone like whoa, obvs). Erlang's open_port/2 function was the perfect solution.
(Okay, I admit, I also really just wanted an excuse to play with Erlang some more. No Starch Press offered to send me free books to review a few months ago, and on a whim I asked for a copy of Learn You Some Erlang for Great Good!. I've been having a lot of fun exploring Erlang on the side ever since the book arrived.
It's a pretty fantastic book, overall - concepts are explained clearly and thoroughly, in a way that I find very intuitive. My only caveat is that I found some of the examples used by the author distractingly offensive - I was really put off by bound variables being illustrated by a sadface dude in a suit standing next to a smiley lady in a white dress. Also, binary gender examples much? So, problematic. But "I like things, and some of those things are problematic." It's definitely also clear, thorough, and informative.)
Waaah don't shell out via Vim please
So, great, user input is bypassing the shell when being sent directly from my Erlang server to Vim. But wait, it's possible to shell out from Vim in various ways! Oh noes, we can't have that.
I'm highlighting matches by using Vim's regex substitution, %s/PATTERN/REPLACEMENT/g. The risky aspect of this is that the REPLACEMENT section can take any vimscript expression, so I don't want users to be able to escape the PATTERN section and potentially get arbitrary code executed that could let them shell out and cause trouble.
This led to a truly absurd bit of Erlang that rejects any user-input pattern with a forward slash preceded by an odd number of contiguous backslashes. Tsk tsk, don't go trying to escape my slash and causing trouble.
Regular Expressions Denial of Service attacks
The other big security risks I fretted over were Regular Expressions Denial of Service attacks. Regular expressions are pretty powerful, and can be written to run dangerously slowly and consume large amounts of memory.
I had a lot of fun testing Virex with this list of Evil Regexes I found on Wikipedia and this fabulous post Dave sent me, In search of an exponential time regex.
The biggest ReDoS problem Vim's regex seems to be susceptible to is greedy quantifiers along the lines of \(.*\)\{1,32000\} - that hung forever. Bummer.
After a bit of poking around, I determined that \{99,\} and \{,99\} were safe, but \{999,\} and \{,999\} are not. So, Virex rejects repetitions that are 3 digits are longer.
Here's the function I'm using to test whether a user-input regex pattern is safe:
safe(Pattern) when erlang:length(Pattern) > 80 ->
false;
safe(Pattern) ->
DangerousRegex = "\{-?[0-9]{3,}|[0-9]{3,}\\\\?\}|([^\\\\]|^)(\\\\\\\\)*/",
re:run(Pattern, DangerousRegex) =:= nomatch.As you can see, I'm limiting patterns to 80 characters on basic principle - if you need to test a longer regex than that, you can do it when you get home.
If the pattern is short enough, that long regex I've got there does two other checks - it makes sure that no quantifiers have repeats that are 3 digits are longer, and that no forward slashes are immediately preceded by an even number of backslashes.

(Why so many backslashes? Blame Erlang. I feel like half the time I spent on this little project was focused on making sure I was escaping characters properly as they went through Erlang, Vim, and oh god you got your regex in my regex.)
So.
To sum up - Virex is a webmachine app, with nginx acting as a reverse proxy and serving the static content, which sanitizes the user-input regex patterns and sends them off to Vim to test them out. Alex Feinman designed that awesome logo for me. The source code is here.
I adore Erlang's syntax, and I had a lot of fun exercising the paranoid portion of my brain and exploring evil regexes - hopefully I caught them all. If you can think of anything else I ought to test for, please let me know! (Ideally via twitter or pull requests, not by crashing my server, thankyouverymuch. ^^)
23 Jul 2013
Ruby: Case versus If (and a wee bit about Unless)
My awesome brother-in-law is learning coding generally and Ruby specifically lately, so we decided to check out ScreenHero and try some remote pairing.
One thing led to another, and next think you know he was asking me how you know when to use a case statement versus when to use if/elsif. We chatted about logic and clean design, and then started wondering if there really was a performance difference between case and if/elsif.
(Yes, yes, this sort of micro-optimization is usually way less important than readable and easy to maintain code. But it's still fun to think about!)
"If you find you're looking to optimize that intensely you probably don't want an interpreted language.
I generally try to avoid case statements simply because it makes it easy for me or another programmer to come along in the future and add another case, increasing the branching in a bit of code that should probably have only done one thing in the first place." - Jonan S.
Yep. Agreed on both points. And now that we've acknowledged that this exploration is just for funsies, let's move on.
Midwire ran a few benchmarks and concluded that if/elsif is faster than case because case "implicitly compares using the more expensive === operator".
It's true - case totally uses threequal under the hood! (I mean, there's a reason we say that threequal is for case equality.) But that doesn't feel like the end of the story, so let's see what else we can figure out here.
In some languages, case statements are implemented as hash tables to gain performance over if/elsif chains. Is that true in Ruby? If not, what is going on here? And where can we look for the answers?
THE RUBY DOCS AIN'T GONNA CUT IT THIS TIME
To be honest, I started this exploration by looking through the Ruby docs and clicking to toggle source on case, but there was nothing there. If and case are so fundamental that they can't actually be defined as functions and thus can't be explained by looking at the Ruby sourcecode. We have to look at the parser and compiler to figure out what's going on with them.
Why? Well, scroll down to SICP Exercise 1.6.
Let us assume for the sake of argument that Ruby had if as a language keyword, but wanted to define case in terms of if/elsif/else.
Let's pretend cond is just if, and rewrite this example...
(define (new-if predicate then-clause else-clause)
(cond (predicate then-clause)
(else else-clause)))…more Ruby-ishly:
def new_if(predicate, then_clause, else_clause)
if predicate
then_clause
else
else_clause
end
endWell, okay. Now, what if we tried to use it like this?
irb(main):012:0> x = 0
=> 0
irb(main):013:0> new_if(true, x+=1, x+=2)
=> 1
irb(main):014:0> x
=> 3Whoops! The then_clause and else_clause get evaluated before being passed in as arguments. That's no good. Okay, fine, what if we set up new_if to take clauses as lambdas instead?
def new_if(predicate, then_clause, else_clause)
if predicate
then_clause.call
else
else_clause.call
end
endCool, but what about scoping? We want the clause that ends up evaluated to be able to change variables from the scope outside the conditional. Good thing that's not actually a problem in Ruby, where closures include bindings and don't just close over values from the outer scope.
irb(main):015:0> x = 0
=> 0
irb(main):016:0> new_if(true, lambda { x+=1 }, lambda { x+=2 })
=> 1
irb(main):017:0> x
=> 1If that seems deeply weird to you, you might want to check out this post on how bindings and closures work in Ruby.
But anyways, we know that case doesn't have to take lambdas in Ruby, so we know that this can't be how it works. And if it's not a function defined in Ruby, but is a language keyword instead, we can't really quite figure out what's going on with it just by reading through the docs as usual. Bah, humbug. Where should we look next?
LUCKY FOR US, MRI IS OPEN SOURCE
When in doubt, it's time to refer to primary source materials.
Okay, I see something about NODE_CASE in compile.c. Looks like we go through each NODE_WHEN, deal with array predicates and such, and ultimately add instructions for checkmatch and branchif, like so:
ADD_INSN1(cond_seq, nd_line(vals), checkmatch, INT2FIX(VM_CHECKMATCH_TYPE_CASE | VM_CHECKMATCH_ARRAY));
ADD_INSNL(cond_seq, nd_line(vals), branchif, l1);So, what’s VM_CHECKMATCH_TYPE_CASE? Turns out it’s check ‘patten === target’.
And just look a bit further down in insns.def and we find DEFINE_INSN checkmatch. Of course, it turns out that checkmatch calls check_match, which checks case equality with idEqq, which (again) turns out to be :===.
That was pretty neat. Now, what about this branchif business? Well, it seems to be defined here. Seems pretty straightforward. It looks like both case and if/elsif are implemented as sequences of conditionals and gotos in Ruby, so we can't expect to get the sort of performance boost with case in Ruby like we see in languages where case statements are implemented as hash tables instead.
That doesn't really answer the initial question, though. Threequal, got it, sure. But what if we use === in our if/elsif statements? Is there any other performance difference between case and if/elsif, really?
OPENING UP THE HOOD WITH RubyVM::InstructionSequence
Oh, to hell with primary source materials. Let's just open up the hood ourselves. Have you played with RubyVM::InstructionSequence yet? Seriously, it's just about the niftiest thing around.
Want to see the YARV ("Yet Another Ruby Virtual machine") bytecode your code really ends up translated into? Sure, no prob.
RubyVM::InstructionSequence::compile_file “[t]akes file, a String with the location of a Ruby source file, reads, parses and compiles the file, and returns iseq, the compiled InstructionSequence with source location metadata set.”
We can verify stuff pretty easily this way. Let's start by testing out a case statement:
number = 15
case number
when 15
'fifteen'
when 5
'five'
when 3
'three'
else
number
end== disasm: <RubyVM::InstructionSequence:<main>@./case.rb>===============
local table (size: 2, argc: 0 [opts: 0, rest: -1, post: 0, block: -1] s1)
[ 2] number
0000 trace 1 ( 1)
0002 putobject 15
0004 setlocal_OP__WC__0 2
0006 trace 1 ( 2)
0008 getlocal_OP__WC__0 2
0010 dup
0011 opt_case_dispatch <cdhash>, 35
0014 dup ( 3)
0015 putobject 15
0017 checkmatch 2
0019 branchif 42
0021 dup ( 5)
0022 putobject 5
0024 checkmatch 2
0026 branchif 49
0028 dup ( 7)
0029 putobject 3
0031 checkmatch 2
0033 branchif 56
0035 pop ( 10)
0036 trace 1
0038 getlocal_OP__WC__0 2
0040 leave
0041 pop
0042 pop ( 11)
0043 trace 1 ( 4)
0045 putstring "fifteen"
0047 leave ( 11)
0048 pop
0049 pop
0050 trace 1 ( 6)
0052 putstring "five"
0054 leave ( 11)
0055 pop
0056 pop
0057 trace 1 ( 8)
0059 putstring "three"
0061 leave And an if/elsif:
number = 15
if number == 15
'fifteen'
elsif number == 5
'five'
elsif number == 3
'three'
else
number
end== disasm: <RubyVM::InstructionSequence:<main>@./if.rb>=================
local table (size: 2, argc: 0 [opts: 0, rest: -1, post: 0, block: -1] s1)
[ 2] number
0000 trace 1 ( 1)
0002 putobject 15
0004 setlocal_OP__WC__0 2
0006 trace 1 ( 2)
0008 getlocal_OP__WC__0 2
0010 putobject 15
0012 opt_eq <callinfo!mid:==, argc:1, ARGS_SKIP>
0014 branchunless 22
0016 trace 1 ( 3)
0018 putstring "fifteen"
0020 leave ( 2)
0021 pop
0022 getlocal_OP__WC__0 2 ( 4)
0024 putobject 5
0026 opt_eq <callinfo!mid:==, argc:1, ARGS_SKIP>
0028 branchunless 36
0030 trace 1 ( 5)
0032 putstring "five"
0034 leave ( 4)
0035 pop
0036 getlocal_OP__WC__0 2 ( 6)
0038 putobject 3
0040 opt_eq <callinfo!mid:==, argc:1, ARGS_SKIP>
0042 branchunless 50
0044 trace 1 ( 7)
0046 putstring "three"
0048 leave ( 6)
0049 pop
0050 trace 1 ( 9)
0052 getlocal_OP__WC__0 2
0054 leave Let's pause for a moment and make some predictions. What do you think this all might mean?
(a/k/a Dear rabbit hole: I'm in you.)
Personally, I'm pretty intrigued by the fact that if/elsif uses branchunless, while case uses branchif. Based on that alone, I'd expect if/elsif to be faster in situations where one of the first few possibilities is a match, and for case to be faster in situations where a match is found only way further down the list (when if/elsif would have to make more jumps along the way on account of all those branchunlesses).
BENCHMARK ALL THE THINGS
To hell with reading the bytecode. Let's just benchmark some shit.
Here's my rough little benchmarking code. I actually tested if/elsif twice: once with ==, and once with ===.
I tested each option with a list of 15 predicates, ranging from 15 as the first down to 1 as the last. So according to my prediction, case should be fastest if I test with n == 1, and slowest when n == 15.
I ran the benchmark a bunch of times, and got results pretty consistently along these lines:
n = 1 (last clause matches)
if: 7.4821e-07
threequal_if: 1.6830500000000001e-06
case: 3.9176999999999997e-07
n = 15 (first clause matches)
if: 3.7357000000000003e-07
threequal_if: 5.0263e-07
case: 4.3348e-07Benchmarking seems to mostly confirm our theory, except note that that threequal_if (a sequence of if/elsifs comparing with ===) was the slowest in both cases. It was slower by an order of magnitude when the last clause matched (n == 1), where both branchunless and the expensive === comparison were slowing it down, and even when the first clause matched (n == 15), when my guess is that the slowness of === outweighed the slowness of the single extra jump case had to make because of branchif.
(When I was initially writing this post, I had some messed up benchmarking and ended up way down the rabbit hole reading about branch prediction optimization, which your CPU deals with. This paper was interesting, too. But never mind that now.)
Anyways. None of this is dispositive, but we have some evidence and a better understanding of how things are implemented here, which is ultimately the real point.
And speaking of rabbit holes, I wonder why case and if/elsif have that different branching... something about different assumptions about how they'd be used, maybe? What about unless?
n = 1
unless n == 1
puts "sadface"
endAs one might expect, unless uses branchunless (like case, and unlike if).
== disasm: <RubyVM::InstructionSequence:<main>@./unless.rb>=============
local table (size: 2, argc: 0 [opts: 0, rest: -1, post: 0, block: -1] s1)
[ 2] n
0000 trace 1 ( 1)
0002 putobject_OP_INT2FIX_O_1_C_
0003 setlocal_OP__WC__0 2
0005 trace 1 ( 2)
0007 getlocal_OP__WC__0 2
0009 putobject_OP_INT2FIX_O_1_C_
0010 opt_eq <callinfo!mid:==, argc:1, ARGS_SKIP>
0012 branchunless 17
0014 putnil
0015 leave
0016 pop
0017 trace 1 ( 3)
0019 putself
0020 putstring "sadface"
0022 opt_send_simple <callinfo!mid:puts, argc:1, FCALL|ARGS_SKIP>
0024 leave And there you have it. Any conclusions I might draw from that would be pure speculation, so I'll leave the facts to stand on their own merits. Knowing is half the battle &c.
Hope this answers your question, Dan! And gives you a few extra tools for looking into the next few as well. ^^ Hooray for rabbit holes!
12 Sep 2012
How I administer little treats to myself
It turns out that Twilio doesn't allow "spoofing" - you can't specify a from_number that isn't a Twilio number, so I can't just forward a text to a random charity directly, which is what I wanted to do in the first place. Bummer!
So instead, now I (or you, if you're into that kind of thing) can text 347-756-4559 with '5' or '10', and it will send back the phone number and code needed to donate that amount to a random charity off the list. (Text anything else, and it'll ask for a 5 or a 10 kthxbye.)
Walking down the street, pass a Starbucks, get that urge to grab a mocha? Feh, just text to get info on a charity that takes $5 donations by text, and send in one of those instead. Don't like the charity returned? Text again to roll the dice again, as it were.
List of charities adapted from here. My modified list is somewhat personalized, with a strong emphasis on charities that focus on medical research and poverty relief over religious institutions.
Just a tiny little simple Flask app, but it really does make me happy.
16 May 2012
Honey from Huffman trees
Did you know that NYC Open Data includes latitude/longitude for every tree in NYC? A tree census - amazing! Surely there's something fun we can do with that!
Well, bees in NYC do a lot of their nectar foraging from flowering trees. It could be interesting to see which kinds of trees my bees are likely foraging from. Bees can fly startlingly long distances to forage if they have to, but my sense is that a 2 mile radius is a decent rough estimate for how far they're likely to fly in search of nectar barring a barren neighborhood. Sure, there are plenty of other flowering plants in the city (I can certainly taste the clover in my spring honey, for instance), but it's still interesting to see which trees are likely contributing to the honey I harvest locally.
So, I pulled the tree census data into mysql to play with. (Bread crumbs for the inspired: I wanted to deploy on Dreamhost, so I used an old version of mysql and was stuck with mbrcontains narrowed down with the haversine equation (and cosine approximation, of course) to find only those trees actually within an n-mile radius of my starting point. Postgres and stcontains with a polygon approximation of the circle would be better, really.)
I'm displaying results as a Huffman tree - a visual representation of the data structure you create when you use Huffman encoding.
Visualized with D3.js, with leaf sizes proportional to the percentage of trees found of each type, it looks rather like this:
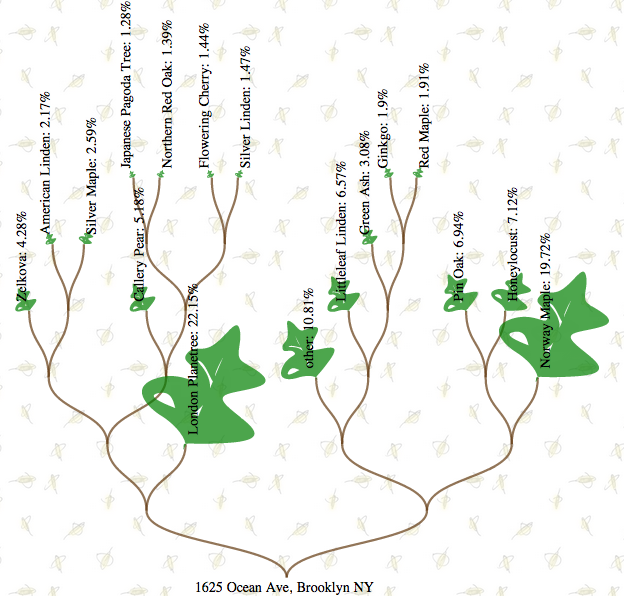
You can put in your own beehive address (or home, or neighborhood you're thinking of moving to, whatever makes you happy) and play with my tree-finder here.
When a thing is as dorky as it can possibly be, I know it is done right.