30 Mar 2012
Kenobi: a naive Bayesian classifier for Ask Metafilter
I built Kenobi as a way to get my feet wet with machine learning.
A fellow Recurser had mentioned the idea of a naive Bayesian classifier to me, and my ears perked up - Bayes! Hey, I know Bayes' Theorem! It's a generally useful simple equation that helps you figure out how much or how little to take new evidence into account when updating your sense of the probability of something or other.
The basic idea is: 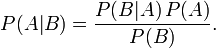
Wait, no, the basic idea is that evidence doesn't exist in a vacuum. Bayes' Theorem is a way of quantifying how to look at new evidence in the context of what we know already and understand how we should weigh it when taking it into account, and how to determine more accurate probabilities and beliefs given the evidence we have to work from. If you're looking for a more detailed understanding, I highly recommend reading Yudkowsky's particularly clear explanation of Bayes' Theorem.
(I went to a rationalist party once. Some guy asked me, "Are you a rationalist?" The friend who'd dragged me to the party interrupted with, "Well, she's not not a rationalist!" And there you have it, I suppose.)
So, that seemed like fun. I'd just finished working on a card game implementation that can run simulations of strategies to help my partner with his game design (Greenland), and was ready for a new project. But a spam filter seemed dull - it's been done before. Repeatedly. So, what to do?
I'm a huge fan of Ask Metafilter, a community where folks ask questions (shocking, no?) and answer questions asked by others. My fabulous brother got there first, and I appreciate that he dragged me in with him. It can be a bit overwhelming, though. I don't really have the time to skim through all the questions that get posted, especially since so many of them are about things where I have no useful information or advice to give. It sure would be helpful if something pared the list down to only the questions where my answers would be most likely to actually help others, right? Right!
Kenobi was a perfect combo project for me. I got to explore machine learning, use some of the skills I picked up at the awesome ScraperWiki class on web scraping I took a while back, and create a tool I'd actually use to improve my ability to help others. Right on.
So, what does Kenobi actually do?
Kenobi has two basic functions: analyzing answers you've already posted to old AskMeFi questions, and classifying new questions for you to pick out the ones you can answer best.
To analyze your old AskMeFi data, Kenobi:
- deletes outdated training data for you from its own database, if any;
- logs into Metafilter under a spare account I created for this purpose, because one can't see favorite counts in user profile comment data unless one is logged in;
- searches to find the user ID number associated with your username;
- scrapes the answers section of your profile for the above-the-cut text of each question you've answered, and whether or not you've received at least one favorite on the answer(s) you posted to that question;
- separates the old questions into a "should answer" group (those where your answer(s) did get at least one favorite) and a "should NOT answer" group (those where your answer(s) didn't get any love);
- organizes and saves the data from each group ("should answer" and "should NOT answer") to refer back to when classifying new questions;
- compresses the data to save space in the database; and
- emails you to let you know that training is done, if you submitted an email address (highly recommended).
To classify new AskMeFi questions for you, Kenobi:
- clears out your last batch of results, if any;
- parses the Ask Metafilter RSS feed for above-the-cut question text and URLs for the n most recent questions;
- decompresses the data it has on you into memory;
- for each question, determines the probability that you should answer it and the probability that you should NOT answer it, based on Bayes' Theorem and your old answer data;
- for each question, if the odds that you should answer it is at least 4.5 times higher than the odds that you should NOT answer it, classifies that question as good for you to answer;
- saves and displays only and all the new question that are classified as good for you to answer.
Why do the odds that I should answer a question have to be 4.5 times higher than the odds that I should NOT answer that question, for Kenobi to classify it as good for me?
Because when I left the threshold lower, people were getting too many questions that didn't seem like good fits to them. With a higher threshold, some folks may not get any results at all (sorry!), but people who've answered enough past AskMeFi questions to give good data to work from will get much more accurate results.
The closer the two probabilities are, the less confident we can be that we've really found a good match and that the question really is a good one for you to answer. It only makes sense to select a question for you when the odds that it's the kind of question you're good at answering are significantly higher than the odds that it isn't.
Why all that compressing and decompressing?
I wrote Kenobi up as a pure Ruby command line tool first, then decided it would be fun to quickly Rails-ize it so more people would be able to play with it more easily. That meant finding a place to deploy it, as easily and cheaply as possible.
Heroku (my host) charges for databases over 5mb. I love you all, but not enough to spend money on you if I don't have to. I'm trying to be as efficient as possible here, in hopes of not going over and having to actually spend money on this project if I can possibly avoid it.
Why the wait while Kenobi analyzes my old data?
A few reasons!
First, one can't actually effectively search Metafilter for a user by name or see favorite counts on the list of a user's past answers in their profile unless one is logged into Metafilter. Metafilter doesn't even have an API to work with. It does have info dumps, but they're huge and not updated regularly.
This means that Kenobi has to arduously scrape and parse the html for Metafilter whenever it analyzes old data for a new user. And it has to actually log into the site and click through as a logged-in user to do so, which it does using a gem called Mechanize.
I set the scraping up as a background task with Delayed_Job and set Kenobi up to email people when ready, so no one had to sit around staring at an error message or colorful spinner while waiting for their analysis to come up in the job queue and get done. This meant that there were no more http timeout error, but it also means that your analysis job goes to the end of the queue, however long it may be.
Also, Heroku charges for worker dynos, which are needed to actually run the background processes piling up in that job queue. They charge by the second. (Seriously). But that includes all the time the worker spends sitting around waiting for a job to exist, not just the time it spends actually working on jobs.
This was just a learning project, not something I actually expect to earn anything from or want to pay anything for. So, I spent a bunch of time messing around with a nifty tool called Workless and learning how to have Heroku automatically scale a single worker dyno up and down as jobs are added and completed, so I can pay for as little time as possible.
This slows things down for you even more, because not only are you waiting for the scraping to get done, you're actually waiting for Heroku to start up a new worker dyno to start working on the scraping before it can get done.
Sorry about that! If you care a lot for some reason, email me and we can commiserate or something.
Wait, so Kenobi picks out questions where my answers will help others, not questions that help me directly?
That's right! Kenobi's selections are based on each new question's similarity to the past questions to which your answers have been favorited by others, and dissimilarity to the past questions where your answers got no love. It doesn't pay attention to what you've favorited - only to which of your answers have been favorited by other people. It doesn't really care about your interests at all, other than your interest in being popular of use to others.
Have fun!