
the best way to accept payments online
Game Days
injecting failures
into running applications
Who are we?
Happy Captain Picard Day!

Why do we run
game days?
Things might blow up!

explosions are better
when we're awake
If you die in prod...

Controlled experiments,
not chaos
An investment in
reliability
C'mon, let's break stuff!

There are so many
failure modes
we could try!
Single node failure
- Process failure (`kill STOP`, `svc -d svcname`)
- Machine failure
- Machine reboot (`echo b > /proc/sysrq-trigger`)
- Disk failure
- Disk degradation
- Disk full
- Out of file descriptors
- Network degradation
- CPU degradation
Correlated node failures
- Machine failures
- Disk failures
- Disk degradations
- Disks full
- Network degradations
- CPU degradations
Network partition
- Between availability zones
- Between services
- Within services
Misbehaving users
- Denial of Service
- Malicious input
Database failures
- Autoincrement field exhausted
- Indexes missing
- Healthchecks fail?
Non-routine operations
- Launching instances
- Terminating instances
Okay, but which
failure modes
can we test
easily?
A few easily tested examples
- Process failure
- Machine failure
- Network partition between services
- Denial of Service
- `sudo rm -rf /`
low-risk tests at first

Prepare hypotheses
in advance
Warn people!

Planning experiments


instance failure

hypotheses
- Latency should be fine
- Alerting: no pages, only emails

Latency was fine, yay!

Do we really wanna get paged over this?
network partition

hypotheses
- Charges should go through successfully, just without being scored
- Latency should be fine
- Alerting: We should get paged!
partition the network
iptables -A ... DROP
Oh noes, latency spiked!

repair the network
iptables -D ... DROP
Better timeouts would be nice...
let's kill
our redis cluster's
primary node
kill -9 $REDIS_PID
A little
healthy fear
hypotheses
- One of the secondary nodes should be promoted to primary
- When the old primary node comes back up, it should come up as a secondary
- Scoring should continue normally
- Unless things don't go as above, no one should get paged
Where's our data?!

time to clean up

What happened?!
Well, we'd recently turned off snapshotting on our primary node...
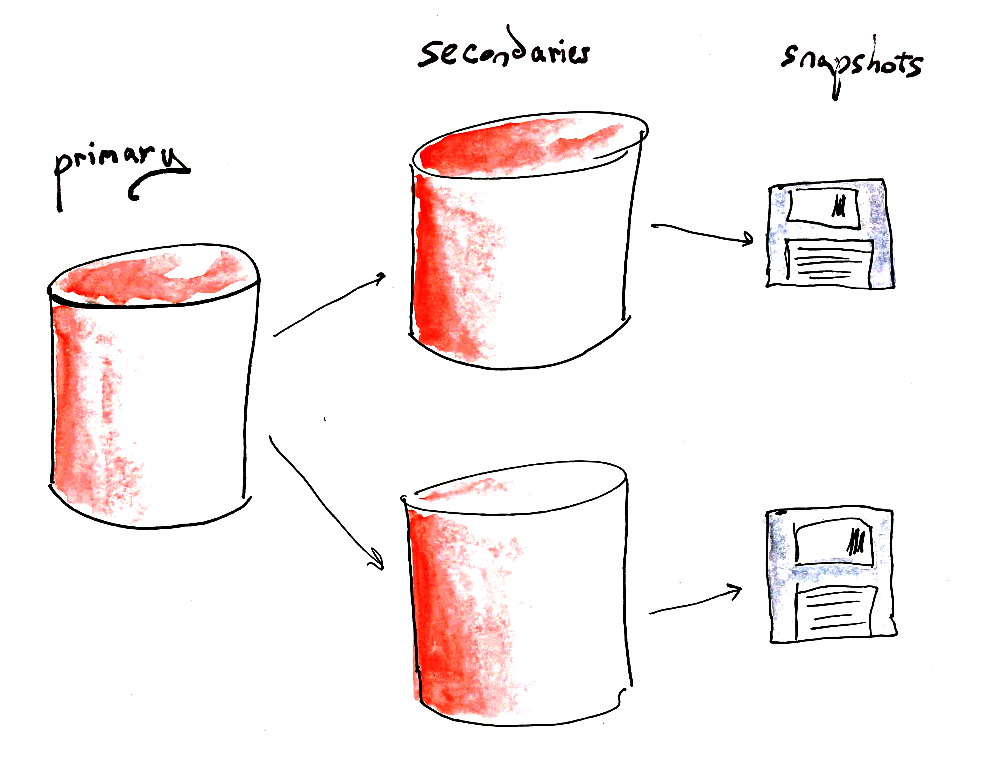
failover didn't happen...


![Bad [database] romance](./images/gameday/badromance.jpg)
